こんにちは。エイチームライフデザイン技術開発室の鈴木です。普段は言語モデルを用いた研究開発をしています。
最近ChatGPTが話題ですね。エイチームグループでもOpenAI APIを利用して、エンジニアに限らずビジネスのメンバーも交えて有効活用できる方法を模索しています。
ChatGPTはWEB上のUIなどから普通に使う分には特別な知識は必要ありませんが、APIなどから使う場合「Top P」や「Temperature」といったパラメータがあります。

画像はOpenAI Playgroundの画面ですが、「Temperature」や「Top P」を設定する項目があります。
OpenAIの公式ドキュメントなどによると、これらのパラメータは確率分布に関する値であり、低い値にするほど決定的・再現性のある出力になり、高い値にするほど多様な出力になるというような事を言われています。これらのパラメータがどういった意味なのか、すこし踏み込んで調べてみましょう。
※ChatGPT(GPT-3.5およびGPT-4)はAPI経由でのみ提供されており、Top PやTemperatureというパラメータが実際にどういう扱いをされているか中身の処理はブラックボックスです。本稿で述べる内容の一部は、ChatGPT自体の仕組みではなく大規模言語モデルとして一般的に言われている内容、特にオープンソースで提供されているGPT-2の各種実装に基づいています。
前提知識: 言語モデルと確率
Top PとTemperatureは、いずれも確率にまつわるパラメータです。これらを理解するためには、言語モデルと確率の関係を知っておく必要があります。
狭義の言語モデルとは「文章の尤もらしさをモデル化した(数式に落とし込んだ)もの」です。たとえば以下の3つの文を見てください。
- A: 吾輩は猫である
- B: 吾輩は犬だ
- C: 吾輩は今日はいい天気ですね
「吾輩は」と言われたら、夏目漱石の有名な文学作品から「吾輩は猫である」を思い浮かべる方が多いのではないでしょうか。Bの「吾輩は犬だ」という文も間違っているわけではありませんが、「猫である」と続くほうが尤もらしいと考える方が多いのではないでしょうか。 一方でC「吾輩は今日はいい天気ですね」という文は文法的にも間違っており、こんな文はほとんどありえないと言えます。
A、B、Cの3つの文章の尤もらしさ、つまり生成される確率を定量化した値をそれぞれとおくと、以下の関係が成り立っている、といえます。
このように、文章に対してそれが生成される確率を出力するものが言語モデルです。
一方で「吾輩は犬だ」という文も間違っているわけではないので、「吾輩は猫である」という文と同じくらいの確率であるべきだ、という主張もあると思います。以下のような関係のほうが妥当かもしれません。
このように言語モデルの定義は様々です。「良い」言語モデルというのは、この確率分布の精度が高いモデルです。GPT-3.5よりもGPT-4の方が「良い」言語モデルだというのはどういうことかというと、より精度の高い確率を出力するモデルということだと言えます。1
言語モデルによる文章の生成
言語モデルによって文の生成確率が与えられる事が分かりました。言語モデルを使って文章をどのように生成するのかを、もう少しだけ踏み込んで考えてみます。
先ほどは「吾輩は猫である」という文が一度に与えられたときの確率を考えましたが、ある入力を受け取って続きの文章を生成するような動作を考えます。
ここでは入力として「吾輩は」だけが与えられた時を考えましょう。「吾輩は」に続く出力が語となる確率は、条件付き確率
と表す2ことにします。
として「犬」「猫」「今日」といった様々な語を検討して、言語モデル上での確率がどれくらいなのかを調べます。
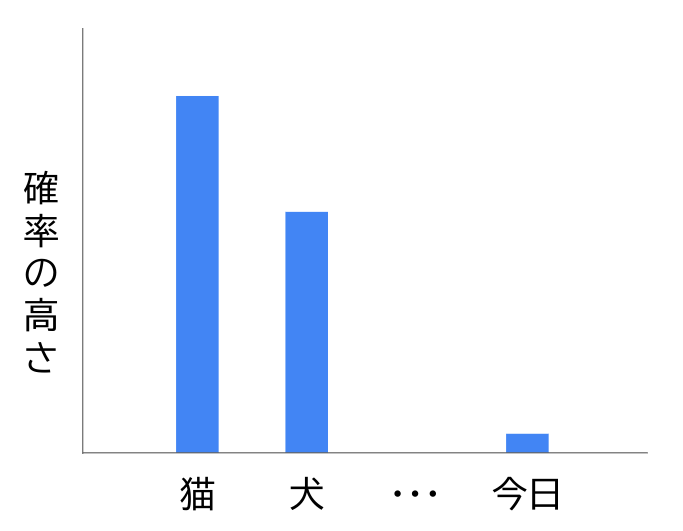
として色々な語を入力しながら確率
を考えた時、
とするのが良さそうだとします。そこで次は「我輩は猫」までを入力として
を考えます。このように、言語モデルを使って生成した文を次の入力として再帰的に計算していくことで、最終的に「吾輩は猫である」のような文を生成できます。
- 「吾輩は」に続く語 = 「猫」
- 「吾輩は猫」 に続く語 = 「である」
さて、を考えた時に「
とするのが良さそう」という曖昧な表現でごまかしました。
というのはどうやって導き出すのでしょうか。単純に考えると、
が最大になる
を考えれば良さそうですが、必ずしもそれが最適な方法ではありません。
が最大になるような
、つまり「吾輩は」に続く確率が最も高い語が「猫」だったとして、次は
が最大になる
...のように最大となる語を選び続ける手法を 貪欲法(Greedy Search) と呼びます。この貪欲法は、必ずしも最適な方法ではありません。貪欲法では、確率の低い語の先にある確率の高い語を見逃してしまうからです。
最後まで生成した文、ここでは「吾輩は猫である」まで生成したときの確率が最も高くなるように選択することが、本当の最適な解となります。 「吾輩は」に続く語として確率が高いのは「猫」だったとしても、完成した文を考えた時に「吾輩は猫である。名前はまだ無い」よりも「吾輩はと言われたらみんな猫であると続けたがるが、それは夏目漱石の文学作品の影響である」という文のほうが確率が高いという事が考えられます。
ですが最適な文章を生成をするには、言語モデルの知っているすべての語彙をすべての順番で並べたときの確率をすべて計算する必要があります。それは計算のコストが膨大にかかってしまい現実的ではありません。そのため言語モデルによって与えられた確率を用いて、できるだけ少ない計算コストでより良い文を生成できるよう、貪欲法をはじめ様々な手法(サンプリングアルゴリズム)が考えられています。
色々述べましたが、ここでは
- 言語モデルとは文章の生成確率をモデル化したもの
- 言語モデルで文章を生成するとき、必ずしも確率が最も高い語を選び続ける事が最適ではなく、様々な手法が組み合わされている
ということまで理解できていればOKです。
言語モデルから出力された確率を使って、より良い出力ができるようにいろいろ工夫しながら使う必要があります。その工夫のひとつが、Top PやTemperatureといったパラメータに関わってきます。
余談: ChatGPTの出力が毎回変わる理由
ちなみにChatGPTなどの言語モデルは、同じ入力を与えても毎回異なる出力が得られる事があると思います。これはサンプリングアルゴリズムに依存します。
先ほど紹介した貪欲法であれば出力が変わることはありません。ですが様々な手法を組み合わせたとき、モデルの確率分布に従ってランダムに語を選ぶようなプロセスがあると、その選択によって出力が毎回変化します。
Top P: 上位p%のトークンを取得
ここからが本題で、Top Pパラメータについて説明していきます。
Top Pは Nucleus Sampling(Top-p Sampling) という手法で使われるパラメータです。確率分布から語を選ぶ時、最も高い語からの累積確率を数えて上位一定割合の語のみを選択対象にし、それ以下は足切りをします。
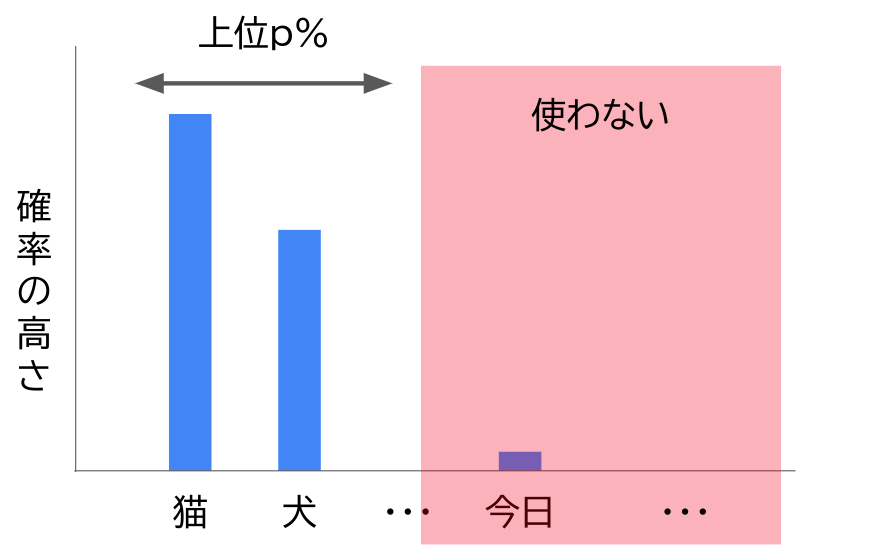
Top Pのデフォルト値は1.0が使われる事が多いと思います。1.0というのはすべての語を選択対象とし足切りをしないということ、つまりNucleus Samplingをしないということです。
言語モデルによってはTop Pを下げることで、あり得ないような出力をすることが減って品質が上がります。しかしChatGPTで使われるGPT-3.5やGPT-4はかなり性能が高いため、品質の向上を目的にTop Pを調整するというよりも、出力の一貫性や再現性を求めて調整することの方が多いのではないかと思います。
Temperature: 確率分布の散らばり具合の調整
Temperatureもまた確率分布にかかわる値です。Temperatureを小さな値にすると確率分布の散らばりが大きくなって、確率の高い語はより高く、確率の低い語はより低くなります。逆にTemperatureが高くなると、確率の高い語と低い語の差が縮まります。

Temperatureの値は言語モデル毎に調整する必要があります。Temperatureの効果が、言語モデルの出力する元の確率分布の散らばり具合に依存するためです。temperature=1.0がデフォルト値として使われる事が多いと思いますが、Top Pのそれとは異なり1.0という値に特別な意味があるわけではない点に注意してください。
Temperatureの計算方法については、Qiitaの拙稿にてGPT-2のオープンソースの実装における例を交えて解説しています。
Top PとTemperatureを調整する時の注意点
ここでOpenAIの公式ドキュメントに立ち戻って欲しいのですが「Top PとTemperatureの両方を同時に変更することは推奨しない」と言われています。これらのパラメータを調整する時は、いずれか1つを変更しながらその効果を確かめるようにしましょう。
まとめ
ChatGPTをAPIなどで使う時に設定できるTop PとTemperatureというパラメータについて解説しました。ChatGPTのGPT-3.5やGPT-4ではこれらのパラメータを意識しなくても高い品質の出力を得られますが、用途に応じて調整する事によって、より求めた出力を得やすくなる場合があります。実際にどういう場面においてどのようなパラメータ設定が効果的なのか調べてみると面白いと思います。